")
Modern-day application development demands a “shift-left” approach, which has moved software testing to the earlier phases of development. As more application developers implement the CI/CD approach, testing cannot be confined to the final phase of the entire cycle.
Even as CI/CD has streamlined application delivery, it has not delivered reliability and performance at the same scale. Despite growing automation, there are increasing levels of production defects, software rollbacks, and performance outages. Over 80% of software development teams experience a production incident every week, and a significant percentage admit to shipping unresolved changes in the face of strict deadlines.
Quality testing is no longer a phase, it’s becoming a service. Without automation, speed and quality remain limited by human capacity. Continuous testing removes this constraint without sacrificing reliability.
This blog is the first in a three-part series exploring how continuous testing is evolving, and how synthetic data plays a foundational role in making quality truly continuous. In this series, we’ll break down why traditional approaches fall short, how modern testing frameworks work, and how synthetic data enables reliable, scalable testing across the CI/CD pipeline.
What is a continuous testing framework?
A continuous testing framework goes much beyond automated testing and implements quality testing as a strategic approach. While test automation tools focus on executing scripts to reduce human intervention, continuous testing focuses on providing real-time insights into business risks at every SDLC stage.
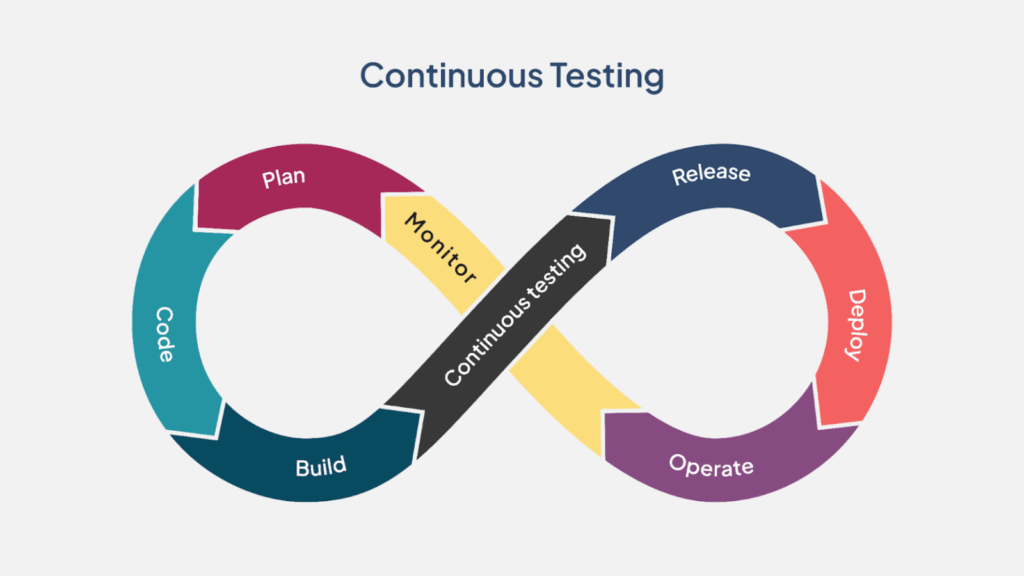
As a quality layer embedded across the entire development process, continuous testing (CT) frameworks implement testing right from the pre-production stage of defining requirements.
Here’s how this framework operates for each of the following:
- Code commits: Automatically triggered by every code commit in the CI/CD process.
- Code integration: While “traditional” code integration is about “merging files,” the CT framework validates every code change before merging with the main codebase.
- Application performance: A CT framework verifies every code change for speed, scalability, and performance, thus avoiding any performance debt. For instance, the performance threshold is limited to a new code change not increasing the “response time by over 10%” or crossing the “500ms” threshold.
- Security testing: While traditional testing is restricted to UI or regression testing, CT frameworks include security testing that checks for security flaws in the written code.
- Feedback loops: Continuous testing delivers a “fail-fast” feedback loop, where the developer gets an immediate alert about a testing failure.
With its architecture-driven testing, CT frameworks ensure that every code is verifiable right from the first day. This architecture ensures a reliable “design for testability” built on the following critical foundations:
- Observability – or the ability to verify the internal system, using APIs, logs, and metrics.
- Controllability – or the ability to manipulate the system into a specific state without any manual setup.
- Isolation – or the ability to test individual components (for example, the Billing module) in isolation.
With this proactive testing approach, product teams can prioritize features and functionalities without needing to debug or resolve architecture-related defects.
Why is continuous testing non-negotiable in 2026?
Here are some of the driving factors that have made CT frameworks non-negotiable in 2026:
- Microservices & distributed systems
CT frameworks ensure that a new codeline (or code change) doesn’t “break” connections with other microservices or APIs. - Cloud-native deployments
“Traditional” test environments are no longer adequate for cloud-native deployments. CT frameworks deliver quality at an infrastructural level for cloud-native applications. - Parallel development
As more companies transition from monolithic applications to microservices, CT frameworks can facilitate multiple teams to work simultaneously on different functionalities without any integration conflicts. - Faster release cycles
With its tight integration into the CI/CD pipeline, CT frameworks can provide feedback to developers within 5 to 10 minutes of code development, thus enabling faster release cycles and improved quality. - Customer experience
With CT frameworks, companies can meet their customer expectations with zero downtime and consistent performance. It can reduce the time gap between product releases, thus leading to higher customer satisfaction.
Industry leaders and senior engineering stakeholders consistently point to one critical dependency for successful CT frameworks: the right data, available at the right time. Yet, despite advances in tooling and automation, test data remains one of the most persistent challenges.
Let’s look at where things break down.
Data-related challenges with continuous testing frameworks
In 2026, complex code management is not a “bottleneck” for CT frameworks, but rather a lack of high-quality production data. With stringent data privacy regulations like GDPR, real-world data is not easily accessible for testing applications. Outdated or incomplete data can immediately fail most CT frameworks, simply because the underlying dataset has not been updated.
Similarly, most CI/CD pipelines require a continuous flow of data to keep running. Traditional data masking techniques can consume a lot of time to process real-world databases. Another risk is the creation of shadow data whenever security protocols are bypassed to meet a product release deadline, resulting in compliance violations.
While modern applications produce massive volumes of data, QA teams cannot pull this data into any testing environment. They can choose a representative set of data (with complex relationships), but this process is technically complex and can compromise referential integrity.
Effectively, CT frameworks lack access to high-quality test data, thus resulting in incomplete validation. As a result, continuous testing often fails when its data is either static, scarce, or insecure.
Why software companies cannot depend on production data
QA teams in software companies can no longer depend on real-world production data for a variety of reasons, including:
- Regulatory practices
With stringent regulations like GDPR and CCPA, data collected from users cannot be used for other purposes, like software testing. These regulations also impose strict restrictions on how to use the customer’s personal information. - Data security
As compared to highly secure production environments, testing environments require less security, which can expose sensitive data to cybercriminals. Additionally, insider threats can arise when QA teams have easier access to sensitive data such as financial records or credit card numbers. - Edge case scenarios
Production data often represents real-world scenarios, but does not include edge cases (or “what could happen”) scenarios – for example, testing a new feature for adding a new user with a 50-character last name. - Massive data volumes
Real-world production data is often massive in volume, which makes it unfeasible to use it in every testing cycle. Besides, as production data keeps changing rapidly, automated tests using a specific data record may fail whenever data is refreshed.
The challenges are clear, here’s an example for further clarity. Trainee pilots aren’t taught on fully loaded aircraft, they train on simulators instead. Simulators are safer, more cost-effective, and prepare pilots for real-world scenarios without real-world risk. In the same way, synthetic data provides realistic, production-like conditions for testing, without exposing sensitive data or violating compliance boundaries.
How synthetic data solutions can support continuous testing
In modern development environments, CT frameworks struggle with massive datasets, which makes it difficult to move them. A synthetic data generator can overcome this challenge by replacing heavy production data with artificially generated datasets that replicate the properties of real-world data (without containing any sensitive information).
Here’s how synthetic data platforms can support CT frameworks by:
- Providing on-demand data.
Production databases often take days or weeks to be updated for use in CI/CD pipelines. Synthetic datasets enable on-demand provisioning by creating a new database for every request in an instant. - Maintaining production-like complexity.
Synthetic data does not simply “mimic” production data. It also maintains production-like complexity by replicating data with referential integrity, statistical distribution, and correlations. - Ensuring zero privacy risk.
As synthetic data is generated artificially, it poses zero risk to data privacy. Synthetic data generation tools deliver data privacy using techniques like rigorous auditing, structural isolation, and mathematical guarantees. - Providing seamless scalability.
Traditional testing frameworks are limited in scalability by the size of their production data. Synthetic data solutions can provide on-demand scalability using techniques like horizontal scaling, parallel execution, and entity-based modelling.
With these capabilities, synthetic data platforms can shift the paradigm from continuous testing to continuous quality.
Conclusion
Modern application development environments can no longer sustain using traditional testing methods. With continuous testing frameworks, software companies can embed QA processes within every stage of the SDLC. That said, these frameworks can be effective only when they are provided with realistic and compliant data.
With real-world production data facing privacy-related challenges, synthetic data platforms can be a viable alternative to “fuel” continuous testing. As an AI-generated synthetic data platform, Onix’s Kingfisher is designed to generate quality synthetic data.
In the next part of this blog series, we’ll delve more into synthetic data, how it’s suited for CT frameworks, and how it can address bottlenecks faced by DevOps teams.
Contact us to know more.








