
Every CTO is aware of the legacy cycle. An existing legacy system is decommissioned after migration. However, after 18 months, there’s the next cycle of implementing a new cloud-native analytics stack or an AI platform. The same migration process is repeated.
The legacy cycle repeats because each migration moves the infrastructure but leaves the institutional knowledge behind. However, structural failure is the inability to preserve knowledge during each modernization process, so enterprises don’t have to start from scratch.
According to Gartner, 83% of data migration projects either fail or exceed their budgets. This isn’t a technology failure but a knowledge failure. The impact is not on infrastructure costs but on constant rework (arising from a lack of institutional memory).
In the first blog of this series, we introduced the Semantic Twin as an institutional memory. This one goes further: what the technology actually changes at the foundation, where data migration is heading, and what it takes to get AI pilots to production at scale.
How the Semantic Twin impacts migration
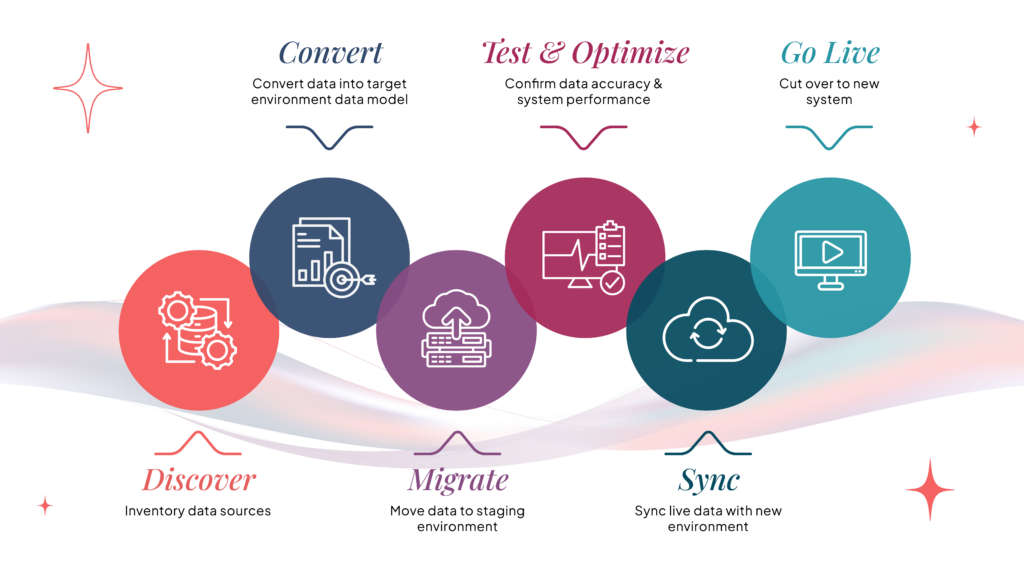
Here’s how a traditional data migration project is undertaken:
- Hire a team of data engineers.
- Implement the discovery process (6-8 weeks) by interviewing stakeholders, tracing data lineage manually, and building dependency maps.
- Implement the technical assessment (4-6 weeks) that includes workload profiling, query categorization (according to complexity), and migration time and cost estimation.
- Execute the actual migration process.
Compared to this manual process, Semantic Twin built by Eagle automates the data discovery phase as a continuously maintained artifact. This means even before the migration, the system has already:
- Developed the dependency map.
- Traced the data lineage.
- Encoded the business context for each data entity.
Raven is Wingspan’s code conversion agent, and because it operates on the Semantic Twin, it already knows the role, dependencies, and lineage of every workload before it converts a single line. With the Semantic Twin already in place, data discovery no longer needs to be rebuilt from scratch at the start of every migration. This is why Onix customers running their data migration on a Semantic Twin experience 3x higher speed.
Why do migration projects run out of context before they run out of budget?
Traditional cloud migration solves the infrastructure problem well. What it has never solved is the knowledge problem. Every service provider stresses the importance of choosing the right tools, the right conversion technique, and the right implementation partner. Even with the advent of new tools and frameworks, the discovery bottleneck is never addressed.
This is largely because most conversion tools operate on the syntax by reading SQL and ETL scripts and translating the dialects. However, these tools cannot answer a question like, “Should this query behave the same way in the new environment, or has the underlying business requirement evolved?” Technology requires a “business context” to answer this question. Context-related information only exists in the brains of system analysts and engineers and is never captured in a persistent (or query-able) form.
Wingspan addresses this directly. The Semantic Twin captures and persists business context across the entire data estate, and Raven, Wingspan’s code conversion agent, reads it before converting a single line of code. This enables it to:
- Understand the query syntax and the business logic.
- Identify the KPIs that it contributes to.
- Recognize if its output is trusted by downstream consumers.
Additionally, Onix’s agent for data movement, Condor, understands data movement not as a bulk transfer but as a context-aware migration that maintains lineage integrity across the transition.
How Onix’s Wingspan delivers 3 outcomes
Each of these outcomes begins with migration and compounds because the Semantic Twin carries forward everything learned in the process. Wingspan delivers all three in parallel, not sequentially. By sharing a context layer across all three outcomes, the Semantic Twin can execute them in parallel. Each of these outcomes begins with migration and compounds because the Semantic Twin carries forward everything learned in the process. Here are the 3 outcomes:
- Data Platform Modernization
As part of Wingspan, the Raven and Condor execute the migration and data movements with complete awareness. With each migration, this helps discover new lineage paths, capture new business logic, and map new dependencies. - Autonomous operations
Instead of a static threshold rule, Onix’s Pelican tool continuously monitors the data quality against the business context-aware expectations decoded in the Semantic Twin. The Kingfisher tool generates synthetic data (for model training) that preserves the business logic and not some approximate statistical distributions. Besides, Eagle FinOps optimizes the cloud spending by understanding the workload context and if every utilized resource is serving a business purpose. - Connected intelligence
Finally, Onix’s Phoenix tool delivers real-time answers to users’ questions, traced back to governed KPIs and their source data. The answer is a traceable, auditable response that’s grounded in the defined ontology.
Why AI pilots fail to scale – and how to fix it
The previous blog in the series highlighted that only 54% of AI pilots make it to the production phase. The remaining 46% failed largely when exposed to production data. In the production phase, data quality is often unmanaged, while business context shifts with the evolving business model. Hand-coded thresholds worked for a curated dataset, but not for a live production environment.
What’s needed is a governed data foundation that automatically manages both data quality and business context. Running on the Semantic Twin, Onix’s Pelican can detect statistical drift at the business level and know the impact of any source change on data quality. By breaking the KPI relationship used for the AI model training, it delivers a model invalidation warning and automatically fires before the model can corrupt any business decision.
How do intelligence dividends deliver a compounding effect? Intelligence dividends emerge from the accumulation of business context. For every successful project execution, the Semantic Twin gathers more context than the previous project. Eagle also enables autonomous discovery and extension to the twin for every added project, new patterns, and inferred relationships. As a result, every subsequent migration is completed at 40% of the time taken for the previous migration. This is the impact of the compounding effect.
Conclusion
The first 2 blogs of this series have addressed the problem and the solution. However, it still doesn’t determine the right decision about the architecture. Blog 3 addresses questions like:
- How does this architecture fit into our current technology stack?
- Do we replace over 14 years of existing infrastructure?
- Does the Semantic Twin require us to start from scratch?
The next and the last blog in this 3-part blog series is about defining AI readiness in terms of architectural outcome and ushering in the next era of enterprise intelligence.
Want to know more? Contact us today.







